HTTP/3について
はじめに
2022年6月に標準化されたHTTP/3の内容把握になります
概要
の内容を自己流で噛み砕いたものです。
(間違い・違和感等あれば、やさしくご指摘頂けると幸いです)
Software DesignにあるHTTP/3の記事は
大変わかりやすくので、こちらを直接読んで頂く方が断然オススメです!!
HTTPの歴史
HTTP/0.9
1991年に仕様が公開される デフォルトのポート80番を使用し、TCP(Transmission Control Protocol)とIP(Internet Protocol)によって コネクションを確立し、HTTPリクエストを送り、レスポンスを受け取るという流れ
HTTP/0.9の問題点
- 画像のやりとりができない
- レスポンスがエラーかどうか判別できない
HTTP/1.0
1992年に仕様が公開される
HTTPヘッダーフィールドにより、HTML以外のコンテンツもHTTPでやりとり可
HTTPステータスコードにより、 レスポンスのエラー判定可
HTTP/1.0の追加要素
- HTTPヘッダーフィールド
- HTTPメソッド(HEAD, POST)
- HTTPステータスコード
HTTP/1.0の問題点
-1つのリクエストとレスポンスのやりとりでTCPコネクションを閉じる - 3ウェイハンドシェイクするオーバーヘッドが大きい
HTTP/1.1
1997年にRFC2068が発行 1999年にRFC2616が発行
Keep-Aliveヘッダによって、TCPコネクションを使いわませるようになる
(再確立のオーバーヘッドが解消)
HTTP/1.1の追加要素
- Connectionヘッダ
- Keep-Aliveヘッダ
HTTP/1.1の問題点
- Head-of-Line Blocking(レスポンスの順番待ち)
- TLS通信の3ウェイハンドシェイクのオーバーヘッド
HTTP/2.0
2015年にRFC7540が発行 SPDYプロトコルを標準化したもの HTTP2よりバイナリ形式のフレームを利用(HTTP/1.1と非互換)
HTTPレイヤのHead-of-Line Blockingを解消するために、ストリーム多重化
ストリームIDをもつことで、レスポンス順不同で送信できるようになる
ヘッダ圧縮にはHPACKを利用する
HTTP/2.0の追加要素
- ストリームのよる多重化
- 優先度制御
- フロー制御
- 類似ヘッダフィールド
- HTTPヘッダフィールド圧縮
- サーバープッシュ
HTTP/2.0の問題点
HTTP/3.0
2022年6月にRFC9114を発行
もともとHTTP over QUICをいう名称
UDPプロトコルを採用することで、TCPレイヤによるHead-of-Line Blockingを解消させる
暗号化必須にすることで、プロトコル硬直化のリスクを軽減させる
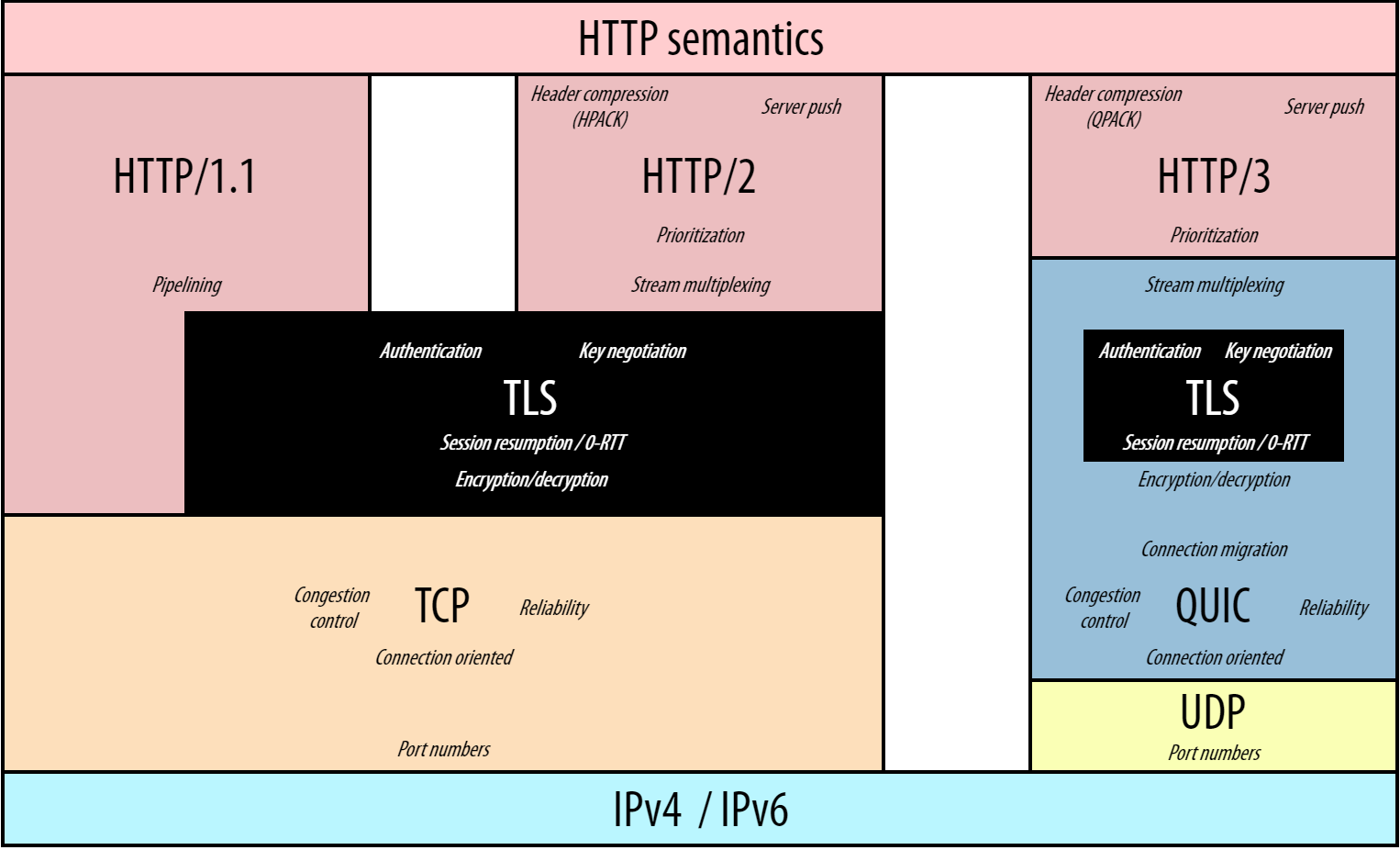
HTTP/3.0の新要素
- ストリームのよる多重化
- Head-of-Line Blocking が発生しない
- 優先制御がシンプル
- 暗号化が必須
- 0-RTT(Round Trip Time)、1-RTTでハンドシェイクが完了
- コネクションマイグレーションが可能
- ヘッダ圧縮にはQPACKを利用
暗号化が必須
トランスポート層における諸問題を、従来のようなTCPを改善するアプローチではなく
UDP+QUICで改善するアプローチ
UDP+QUICにすることで、オーバーヘッドの問題を解消できる
TCPの通信の信頼性はUDPにはないが、QUICにより信頼性を担保させる
QUICのパケット構造
https://datatracker.ietf.org/doc/html/draft-ietf-quic-transport-27#section-17.2
ショートヘッダパケット
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+ |0|1|S|R|R|K|P P| +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination Connection ID (0..160) ... +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Packet Number (8/16/24/32) ... +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Protected Payload (*) ... +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
ロングヘッダパケット
+-+-+-+-+-+-+-+-+ |1|1|T T|X X X X| +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Version (32) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | DCID Len (8) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Destination Connection ID (0..160) ... +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | SCID Len (8) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Source Connection ID (0..160) ... +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
- Connection IDはコネクションの維持、ロードバランサーのアクセス制御
- QUICバージョンはクライアント - サーバー間で合わせるため
スケジュールされたクエリで、各テーブルのレコード件数を自動取集する
週次でテーブルのレコード件数の推移とテーブルの増減を調べたく
ストアド プロシージャの勉強も兼ねて
スケジュールされたSQLで、定期的に収集できるようにしました。
レコードを登録するテーブル名一覧を一時表に登録して
LOOPでメタ情報を順次登録しています。
DECLARE dataset STRING; DECLARE current_row int64 DEFAULT 0; DECLARE loc STRING; SET loc = 'US'; CREATE temp table dataset_list AS ( SELECT catalog_name || '.' || schema_name || '.__TABLES__' AS dataset_name, ROW_NUMBER() OVER (ORDER BY schema_name) AS row_num FROM INFORMATION_SCHEMA.SCHEMATA WHERE location = loc); LOOP SET current_row = current_row + 1; SET dataset = ( SELECT dataset_name FROM dataset_list WHERE row_num = current_row); IF dataset IS NULL THEN LEAVE; END IF; EXECUTE IMMEDIATE FORMAT("INSERT INTO ds.table_metas SELECT *, CURRENT_TIMESTAMP() AS check_timestamp FROM %s", dataset); END LOOP; -- データセット、テーブル登録件数を保持 INSERT INTO ds.records SELECT DATE_TRUNC(CURRENT_DATE(), week(sunday)) AS recorded_on, COUNT(DISTINCT dataset_id) AS dataset_record, COUNT(DISTINCT dataset_id||table_id) AS table_record, SUM(row_count) AS total_record, SUM(size_bytes) AS total_size, FROM ds.table_metas WHERE TIMESTAMP_TRUNC(check_timestamp, week(sunday)) = TIMESTAMP_TRUNC(CURRENT_TIMESTAMP(), week(sunday)) ;
参考にしたブログはこれ以外にもあったのですが。。 qiita.com
いろいろ探してみたけど
そのブログを見つけられなかった。。
どんなキーワードで検索して そのブログへ辿り着けたかも忘れてしまった。 多分、名の知れた方だったかな
もうちょい、ここを熟読しないとな
【備忘録】 __init__.pyの使い方
はじめに
Pythonで、ディレクトリの階層で分けてファイルを管理していますが
今まで、__init__.py ファイルを使っていませんでした...
ファイルを含むディレクトリをパッケージとしてPython に扱わせるには、ファイル __init__.py が必要です。 これにより、 string のようなよくある名前のディレクトリにより、 モジュール検索パスの後の方で見つかる正しいモジュールが意図せず隠蔽されてしまうのを防ぐためです。 最も簡単なケースでは __init__.py はただの空ファイルで構いませんが、 __init__.py ではパッケージのための初期化コードを実行したり、 後述の __all__ 変数を設定してもかまいません。
とのことで、初期化コードを実行と all 変数を設定を試してみたいと
どう試した?
お試しのディレクトリ構成は以下です
├── main.py
└── lib
├── __init__.py
└── logger.py
お試し版のソースは以下の通りです。
init.py
from .logger import Logger logger: Logger = Logger() __all__ = ["logger"]
logger.py.py
from logging import Formatter, getLevelName, getLogger, StreamHandler class Logger(): def __init__(): self.logger = getLogger() self.logger.setLevel(getLevelName("debug")) handler = StreamHandler() handler_format = Formatter( '%(asctime)s : process(%(process)d) : thread(%(thread)d) : [%(levelname)s] : %(message)s') handler.setFormatter(handler_format) self.logger.addHandler(handler) def debug(self, msg: str): self.logger.debug(msg) def info(self, msg: str): self.logger.info(msg) def warning(self, msg: str): self.logger.warning(msg) def error(self, msg: str): self.logger.error(msg) def critical(self, msg: str): self.logger.critical(msg)
main.py
from lib import logger logger.info("hello world")
実行結果
$ python main.py 2022-05-27 20:16:51,917 : process(56990) : thread(4490100224) : [INFO] : hello world
main.pyで、Loggerのインスタンス生成せず(logger = Logger()と書かず)とも、ログ出力ができた。
まとめ
自分に対して言うことは、 ドキュメントをサボらずに読め です。
リンク集まとめ
こちらは、個人的にためになったブログや資料等の単なるリンク集です
- 「スピード」と「品質」のスイッチング ~事業成長を支える生存戦略~
- ソフトウェア開発における『知の高速道路』
- 良いコードとは何か - エンジニア新卒研修 スライド公開
- DeNAデータプラットフォームにおけるデータ品質への取組み
- 情報をデザインする
- データ基盤の3分類と進化的データモデリング
- プロダクトマネジメントと事業開発に関する私的な振り返り
- BigQueryのコスト可視化ダッシュボードを10分で作る
- GitLab Triageでプロジェクトの棚卸しを自動化する
- プロダクト指標の作り方 - North Star Metric
- re:Work と振り返るチーム OKR 2021
- PostgreSQLのロジカルレプリケーション使用時の注意点
- データベースエンジニアから見たCloud Spanner
- RDD Programming Guide
- Spark Streaming Programming Guide
- Apache Spark で分散処理入門
- Directed Acyclic Graph DAG in Apache Spark
- PostgreSQLで自動フェイルオーバーする方法
- edlin - Enterprise direction for Linux
- PGTune
- Data Management Guide - 事業成長を支えるデータ基盤のDev&Ops
- PostgreSQL 13 新機能検証結果 (GA)
- PostgreSQL13 検証レポート
- bashで忘れがちな機能とかいろいろの備忘録
- bashのそれって実はこういう書き方できるよ一覧
- 知らないと損をする「データ分析·サイエンス」サイト37選
- まだExcelで消耗してるの?Pythonによる自動集計ガイド 基礎編
- コードを書く際の指針として見返すサイトまとめ
- BigQueryで単語分割がしたい
- BigQuery におけるコスト最適化の ベストプラクティス
- 情報ボトルネック法を活用した正則化手法Entropy Penalty
- 持続可能な開発を目指す
- Python中級者への道しるべ
- AWS Well-Architected フレームワーク
- データの集計は、ExcelよりPython使ったほうが100倍早い
- 「問題から目を背けず取り組む」 一休の開発チームが6年間で学んだこと
- 【Unity】ソートアルゴリズム12種を可視化してみた
- 正規表現を用いる際のパフォーマンスチェックリスト
- 境界づけられたコンテキスト 概念編
- PostgreSQL 13 の psql 改善項目
- だから僕はpandasをやめた【データサイエンス100本ノック(構造化データ加工編)篇 #1】
- 「実践ドメイン駆動設計」を読んだので、実際にDDDで設計して作ってみた!
- 探索的データ分析の第一歩に便利なpandas-profilingの導入と概要
- "壊れにくい"データ基盤を構築するためにMackerelチームで実践していること
- 無駄分析を無くすためにRettyが取り組んだ3つのこと
- 運用中のPostgreSQLのスキーマを無停止で安全に変更する
- 6,000スロットを使うBigQueryのリソース配分最適化への挑戦
BigQueryのHASH パーティショニングもどきを利用する
BigQueryで
主キー当たる項目にUUID(Universally Unique Identifier)を生成し
こちらの項目に対してパーティション列として使いたい用途がありました。
パーティション分割テーブルについて 公式ドキュメントを読むと
| 取り込み時間 | 日付 | 数値範囲 | |
|---|---|---|---|
| テーブルの分割方法 | データの取り込み時間や到着時間 | TIMESTAMP または DATE列 | 整数列 |
| 分割単位 | 自動で生成される疑似列 | 列を指定 | 列を指定 |
となり、UUID(文字列)は対応しておりません。
公式ドキュメントにあるハッシュ関数を読んだところ farm_fingerprintを見つけました
文字列を数値に変換できますので
次にハッシュパーティションのように利用できるようにするため
UDFユーザ定義関数を定義します。
-- partition_division_sizeは分割する数を指定 CREATE OR REPLACE FUNCTION dataset.generate_partion_no(uuid STRING) RETURNS INT64 AS ( ABS(MOD(FARM_FINGERPRINT(uuid), partition_division_size)) ) ;
パーティション列にデータを登録する際にUDF関数を利用します。
SELECTする際は 以下のようなSQLで取得できます。
SELECT * FROM dataset.table WHERE partition_column = dataset.generate_partion_no(@uuid)
argparseのchoicesで小数点を指定する方法
コマンドライン引数 argparseのchoicesで小数点を指定したいと考えて、よく調べず
parser.add_argument('rate', type=float, choices=range(0.1, 1.0))
こんなイメージでできると思って記述したところ、エラーになりました。。
何か方法がないかと思い、ググってみると こんな感じの記事に遭遇しました。
この手段は、別に悪くはないのですが
別手段はないかなぁと、いろいろな方法を調べてみると
内包表記との組み合わせでイケるんではないかと思って試したらところ
parser.add_argument('rate', type=float, choices=[i / 10 for i in range(1, 11)])
こちらの書き方で無事できました。